 Leif160519的blog
Leif160519的blog
——————
kubernetes 调度简介

一、创建pod的工作流程
概念
- node上所有组件(kubelet/kube-proxy)都是与apiserver通信
- master上两个组件(scheduler/controller-manager)都是与apiserver通信
- apiserver将其他组件通信产生的事件、状态都保存到了与etcd数据库中
- 其他组件与apiserver周期性watch事件。
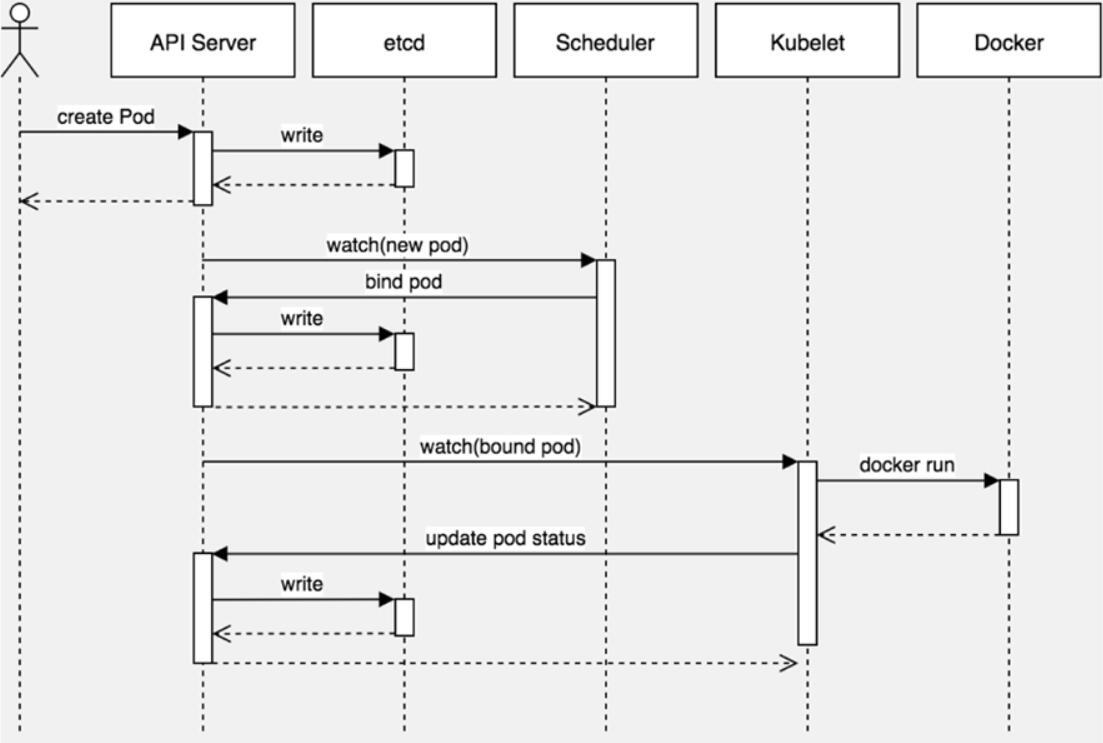
图片解释:
kubectl通过读取集群配置文件(~/.kube/config)将请求发给apiserver,之后apiserver将创建pod的属性信息写入到etcd中,etcd会响应一个状态给apiserver,保存etcd成功会在控制台显示pod/<pod名称> created,之后调度组件(scheduler)上线,负责将新的pod分配到合适的节点上,调度之后,将结果响应给apiserver,apiserver再将结果保存到etcd中,kubelet当发现有个pod被绑定到自己的节点上时,就会调用docker的api去创建容器,容器创建之后,docekr会返回一个状态给kubelet,创建成功之后,kubelet再通知apiserver容器状态,之后apiserver再将状态写入到etcd中,之后就可以使用kubelet get pod去查看pod的状态了
注意:有人会注意到,上图中少了两个组件,分别是
node上的kube-proxy和master上的controller-manager,其中kube-proxy主要负责pod的服务发现和负载均衡,在图片中的位置就是介于kubelet与Docker之间,它的很多工作与kubelet是并行完成的,主要负责提供pod对外访问的一种形式。controller-manager组件主要是完成后台的一些任务,例如deployment与daemonset控制器等,而图片中是不涉及到创建控制器的步骤的,故与controller-manager就没什么关系,如果要创建控制器的话,角色位置介于Scheduler与kubelet之间,它负责创建多少个副本,启动多少个副本,滚动更新等更高级的功能。
总结:
kubectl( .kube/config) -> apiserver -> write etcd -> scheduler -> 调度结果响应给apiserver -> kubelet 发现有分配到我的节点pod -> 调用docker api创建容器 -> 通知apiserver 容器状态
二、影响Pod调度的因素

参数解释:
resources:pod占用的硬件资源(资源调度依据)schedulerName:默认调度器nodeName:Scheduler控制器调度绑定的节点nodeSelector:标签选择器affinity:节点亲和性tolerations:污点容忍
注意:调度器(
schedulerName)除了使用自己的一些默认行为和默认策略之外,也会参考其他调度策略的值(主要参考)。
2.1 resources:资源限制
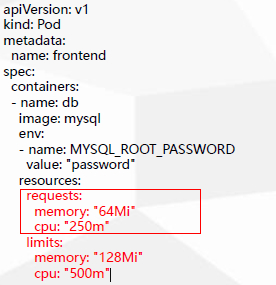
Pod和Container的资源请求和限制:
- spec.containers[].resources.limits.cpu
- spec.containers[].resources.limits.memory
- spec.containers[].resources.requests.cpu
- spec.containers[].resources.requests.memory
参数解释:
- requests:资源请求值,部署资源的最小配合,是调度依据,会根据requests的值去判定当前集群中有无节点去满足请求的量
- limits:资源最大使用
requests必须小于limits的值!
扩展:查看当前节点的资源信息:
kubectl describe node <node-name>
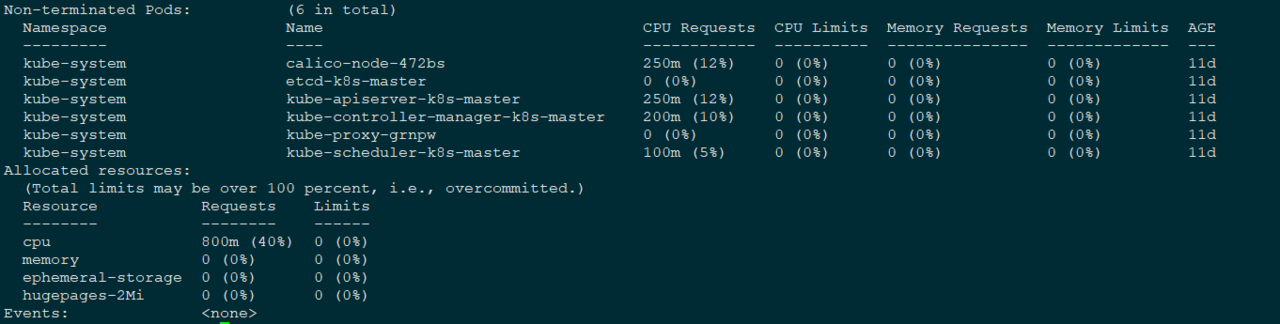
注意: 若pod没有配置resources值,则pod可以使用宿主机所有资源,并且调度不参考配额
建议:requests与limits不要相差太多
2.2 nodeSelector & nodeAffinity
2.2.1 nodeSelector
nodeSelector:用于将Pod调度到匹配Label的Node上
给节点打标签并查看对应节点的标签:
kubectl label nodes <node-name> key=value
kubectl get nodes <node-name> --show-labels
应用场景:适用于多节点,且不同节点配置不一,功能不一的情况。
yaml示例:
apiVersion: v1
kind: Pod
metadata:
name: pod-example
spec:
nodeSelector:
disktype: ssd
containers:
- name: nginx
image: nginx:1.15
注意:若没有匹配到任何标签,则pod会显示pending状态,节点都不可用
2.2.2 nodeAffinity
nodeAffinity:节点亲和性,类似于nodeSelector,可以根据节点上的标签来约束Pod可以调度到哪些节点。
相比nodeSelector:
- 匹配有更多的逻辑组合,不只是字符串的完全相等(
nodeSelector是绝对相等的匹配) - 调度分为软策略和硬策略,而不是硬性要求
a.硬(required):必须满足
b.软(preferred):尝试满足,但不保证
操作符:In、NotIn、Exists、DoesNotExist、Gt、Lt
yaml示例:
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: gpu
operator: In
values:
- nvidia-tesla
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: group
operator: In
values:
- ai
containers:
- name: web
image: nginx
参数解释:
requiredDuringSchedulingIgnoredDuringExecution:硬策略,节点必须满足的条件operator:操作符preferredDuringSchedulingIgnoredDuringExecution:软策略,尝试满足,不是必须满足的条件weight:权重值,范围1-100,值越大,权重越大,pod调度到对应标签的节点概率越高
注意:若硬限制(
requiredDuringSchedulingIgnoredDuringExecution)没有匹配到任何标签,则pod会显示pending状态,节点都不可用,当打完标签之后,pending会变为running状态
补充:
节点亲和性:希望调度到指定标签的节点上;
反亲和性:不希望调度到指定标签的节点上,如使用NotIn,DoesNotExist等
2.3 Taint(污点)
Taints:避免Pod调度到特定Node上
与nodeSelector & nodeAffinity区别:
nodeSelector & nodeAffinity:将pod分配到某些节点。pod属性Taints:节点不允许分配pod。节点属性
应用场景:
- 专用节点
- 配备了特殊硬件的节点
- 基于Taint的驱逐
查看节点污点:
kubectl describe node <node-name> | grep Taint
设置污点:
kubectl taint node <node-name> key=value:<effect>
其中<effect> 可取值:
NoSchedule:一定不能被调度(已经调度的不会被驱逐)。PreferNoSchedule:尽量不要调度(软性)。NoExecute:不仅不会调度,还会驱逐Node上已有的Pod(若pod为设置污点容忍)。
去掉污点:
kubectl taint node <node-name> key:<effect>-
2.4 Tolerations(污点容忍)
Tolerations:允许Pod调度到有特定Taints的Node上
yaml示例:
apiVersion: v1
kind: Pod
metadata:
name: pod-taints
spec:
containers:
- name: pod-taints
image: busybox:latest
tolerations:
- key: "key"
operator: "Equal"
value: "value"
effect: "NoSchedule"
node根据状态也会自动打一些污点:
node.kubernetes.io/not-ready没有准备好(kubectl get node)node.kubernetes.io/unreachable不可调度(kubectl cordon <node-name>)
容忍污点:不是强制性分配到具有污点的节点上,配置了容忍污点,在调度时忽略节点污点
2.5 nodeName
nodeName:用于将Pod调度到指定的Node上,不经过调度器(default-scheduler)
应用场景:
- 调度组件故障,希望临时救急
yaml示例:
apiVersion: v1
kind: Pod
metadata:
name: pod-example
labels:
app: nginx
spec:
nodeName: k8s-node2
containers:
- name: nginx
image: nginx:1.15
2.6 DaemonSet(守护进程集)
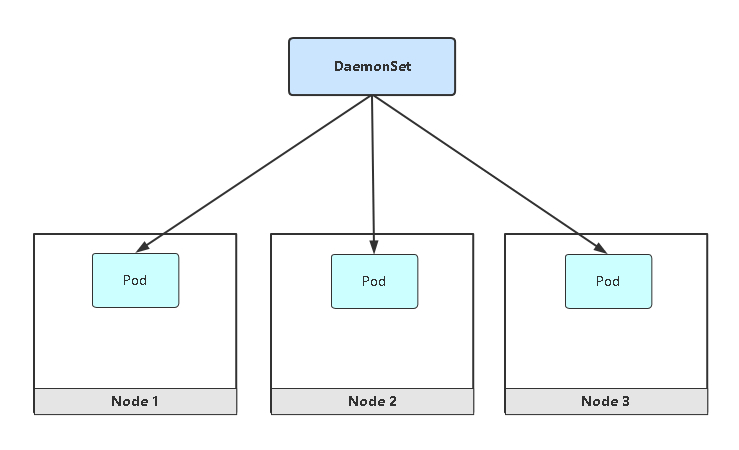
DaemonSet功能:
- 在每一个Node上运行一个Pod
- 新加入的Node也同样会自动运行一个Pod
应用场景:
- 网络插件
- Agent(zabbix-agent监控)
- 日志采集(filebeat)
- C/S架构软件
yaml示例:
apiVersion: apps/v1
kind: DaemonSet
metadata:
labels:
app: web
name: filebeat
spec:
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- image: nginx
name: nginx
resources: {}
通过kubectl get pod可以发现filebeat在每个node上都部署了一个:
[root@k8s-master k8s]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
filebeat-9kc9d 1/1 Running 0 8s 10.244.36.118 k8s-node1 <none> <none>
filebeat-wsbxb 1/1 Running 0 8s 10.244.169.183 k8s-node2 <none> <none>
查看daemonset:
[root@k8s-master k8s]# kubectl get ds
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
filebeat 2 2 2 2 2 <none> 3m2s
三、调度失败原因分析
- 查看调度结果:
kubectl get pod <NAME> -o wide
- 查看调度失败原因:
kubectl describe pod <NAME>
错误解析:
-
没有匹配到标签的提示信息:
0/3 nodes are available: 3 node(s) didn't match node selector. -
没有足够的cpu资源分配:
0/3 nodes are available: 3 Insufficient cpu. -
3个节点有污点,没有配置污点容忍:
0/3 nodes are available: 3 node(s) had taints that the pod didn't tolerate.
“The first 90% of the code accounts for the first 90% of the development time. The remaining 10% of the code accounts for the other 90% of the development time.” – Tom Cargill
标 题:kubernetes 调度简介作 者:Leif160519
出 处:https://github.icu/articles/2020/06/12/1591937242895.html
关于博主:坐标六朝古都南京,服务器运维工程师+桌面运维工程师,如有问题探讨可以直接下方留言。
声援博主:如果您觉得文章对您有帮助,可以评论、订阅、收藏。您的鼓励是博主的最大动力!